
Data quality is at the heart of Kognic. The ground truth, which we are annotating, is however sometimes a bit ambiguous; the limited resolution and sharpness of a camera image usually allows for different interpretations (some other sources of uncertainty are discussed in this blog post), and we often ask ourselves the question on what quality levels are reasonable to expect. The question becomes particularly important when we evaluate tools for automated annotation: how close to a “perfect” annotation is even possible to achieve?

Three careful annotations (blue boxes) of the same car. How much can we reasonably expect them to agree?
To better understand what level of detail we can reasonably expect, we performed a series of in-house experiments. In the experiments we had the same 200 camera images being annotated by 14 different professional annotators, all with the high production quality of Kognic. The images were typical for AD/ADAS applications both in terms of content and technical standard, and bounding boxes were annotated according to a well-defined annotation guideline. Altogether the images contained some 2 500 objects, and with 14 annotations of each we recorded some 35 000 bounding boxes in this experiment. We are therefore confident in our results.
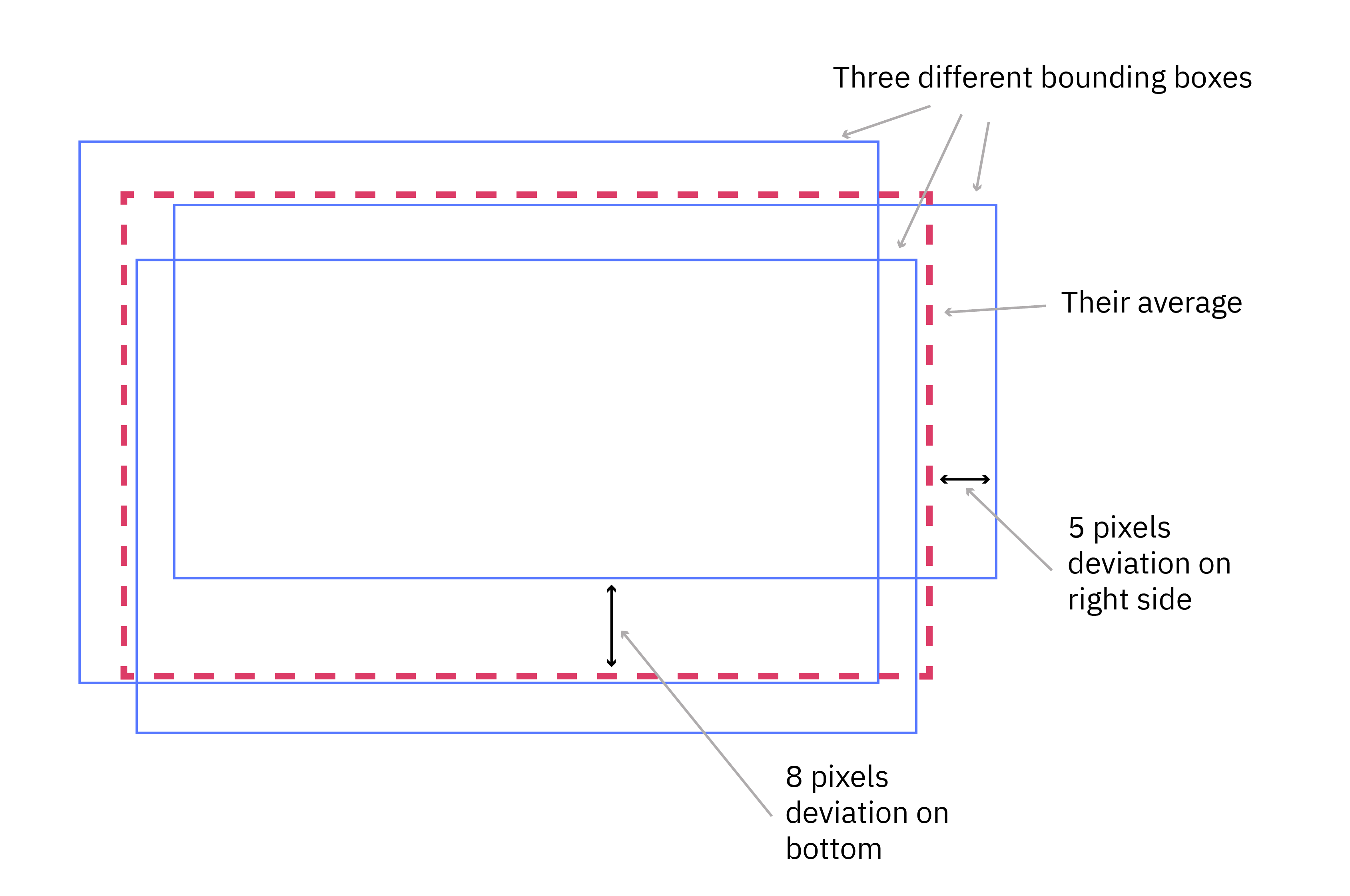
To get the best possible reference annotation, we used “the wisdom of the crowd” and averaged the 14 possibly different annotations to define the ground truth for each object (dashed red in the sketch above). We thereafter studied how many pixels each boundary of each individual annotation deviated from this reference ground truth. The result is summarized in this histogram:
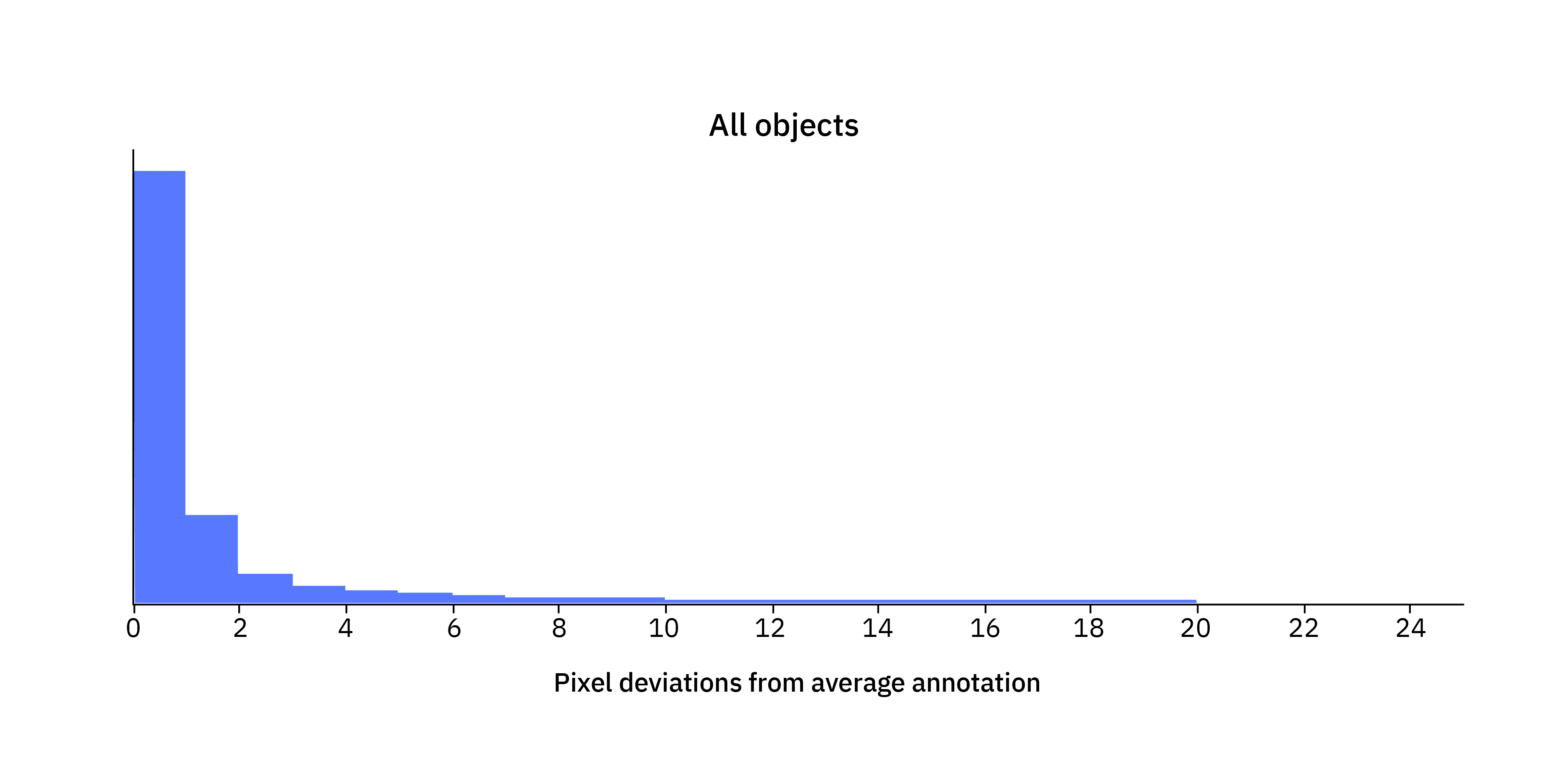
With well-trained professional annotators, it would seem reasonable to expect a high level of agreement between the annotators. And most of the time, that seems to be the case since most pixel deviations are close to 0. However, there is also a significant (and perhaps surprising) share of deviations that are not particularly close to 0 (the most extreme deviations, far beyond the shown range of the histogram, were in fact about 400 pixels). In statistical terms, the distribution has a so-called heavy tail. With some further investigations, we found two important reasons for this heavy tail of large deviations.

Example of a truncated object (the yellow cab), where the annotators have different thoughts on how it extends beyond the image. This is naturally much harder to annotate than if the object had been fully visible in the image.
First of all, the entire object might not be in the image. When parts of the object are outside the image, some ambiguity is introduced if the annotator has to guess how far the object extends beyond the image border. These situations naturally give rise to large deviations between different annotators, and below we can see the deviations filtered only for such cropped objects.

If the ambiguity caused by cropped objects is an issue, it is possible to mitigate it by having an annotation guideline that does not attempt to extrapolate objects beyond the image border. The second cause for large deviations among the annotators is, however, harder to mitigate: occlusion.

Example of an occluded object (the car behind the yellow cab), where the annotators have different thoughts on how far it extends behind the object in front of it. Again, this is much harder to annotate than if the object would have been fully visible.
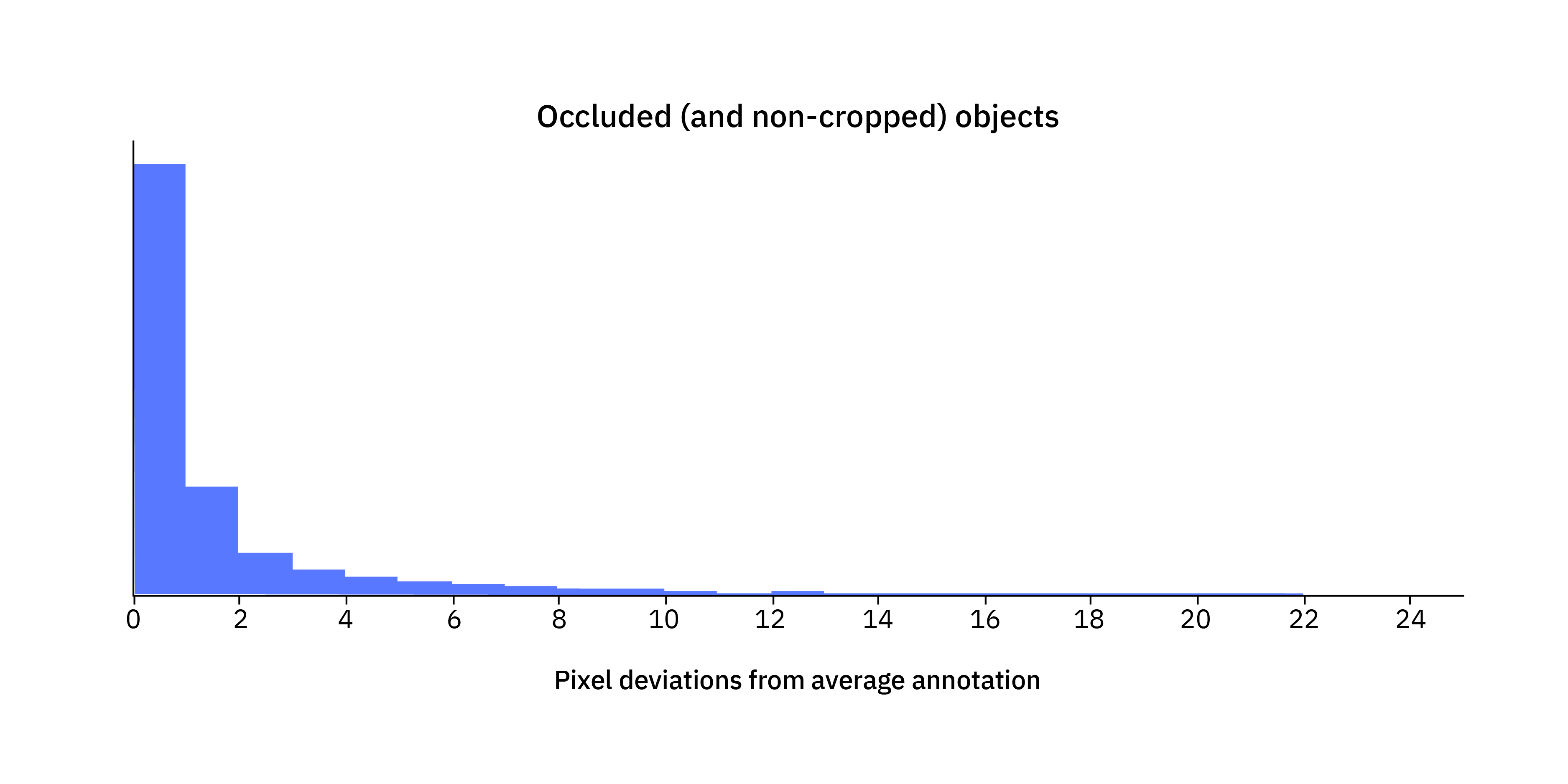
If we filter out the occluded objects among the remaining objects that are not cropped by the image, the deviations look like this. Clearly occlusion is also an important source of ambiguity that causes deviations in the annotations, although it seems slightly less severe than cropped objects.
Having seen that cropped and occluded objects introduce ambiguities in the annotations task that are beyond repair (unless there is additional information available from other sources, such as other cameras, a lidar sensor, etc), the good news is that the remaining non-cropped non-occluded objects seem possible to annotate with high precision.

It has the appearance of a half normal distribution without any heavy tail, and our interpretation of this is that it is reasonable to expect that a careful annotation of a fully visible object in a 2D image rarely deviates more than 2 pixels from the ground truth. However, as we have seen, as soon as an object becomes partially occluded or cropped from the image, the bar drops quickly.
Pixel deviations is a good measure of box placement accuracy for boxes in 2D, but we are also doing annotations in 3D. One of the standard metrics for 3D is intersection over union, IoU. The IoU compares two geometric shapes, and returns a number between 0 and 1. It is 1 if they are identical and 0 if there is no overlap at all. To see what a reasonable expectation for IoU levels in 3D is, we made a similar experiment with multiple annotators annotating the same objects in a 3D Lidar point cloud. We obtained the following result for non-cropped and not occluded objects:
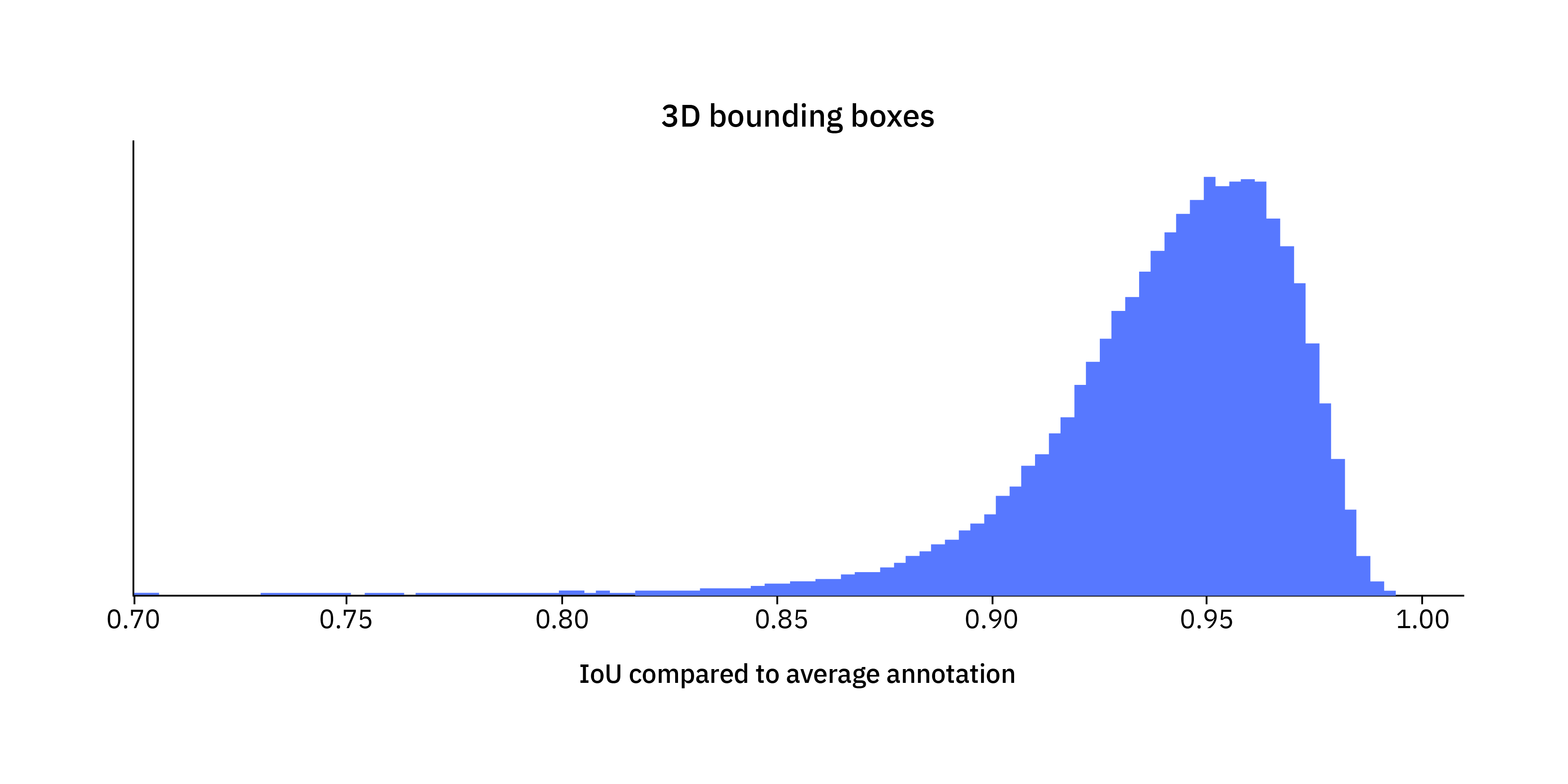
It has the appearance of a beta distribution, and our interpretation here is that it is reasonable to expect that a careful annotation of a fully visible object in a 3D point cloud rarely has a IoU smaller than 0.9 compared to the ground truth. Annotations in 3D are, however, somewhat more complicated than 2D and this is not a hard level but rather a rough idea of what is feasible.
In conclusion, we measured the variance in annotator judgements for a few different scenarios. We concluded that the pixel deviation when annotating images is less than 2 pixels when the circumstances are good. For 3D boxes, the IoU can be larger than 0.9 when the circumstances are good. These insights are important to have in mind when deciding on error tolerances in an annotation project.
Disclaimer: The results in this article are from a specific experiment setup. Although we believe they are of general interest, the conclusions might not be applicable for all annotation projects. Please consult our advisory services to discuss what is possible in your specific project.

