
Achieving self-driving cars is the big challenge of our generation. At Annotell, we think a lot about how to validate the safety of the perception system of autonomous cars. Although there are many commonly used metrics, most of them either lack a clear passing criteria for letting a car on the road, or leave room open for debate around what the value exactly means for the deployment of a self-driving car. Such metrics make it tricky, or even impossible, to actually validate whether an autonomous perception system is really ready to be used.
In this article we will illustrate the problem with current metrics using some examples, and will also propose a simple unit test which would at least show when a car should not be allowed on the road.
Illustrating the problem of traditional metrics

Imagine a self-driving vehicle approaching an intersection as it shows in the images above. The car has a single camera and runs a semantic segmentation network, which distinguishes many different classes such as road, cars, people, bikes and signs. In the coming annotated images down below we have the annotated ‘ground truth’ as found in the CityScapes dataset.
A commonly used metric for semantic segmentation is mean Average Precision (mAP). This calculates precision and recall at different confidence and IoU thresholds for each individual class, and averages this over all classes to get a final metric. It encapsulates the trade-off between precision and recall and maximizes the effect of both metrics. The most obvious problem with this metric when assessing whether a car should be allowed on the road is that there is no specific threshold for when your mAP is high enough to be safe.
For example, if your network perfectly detects all cars and pedestrians, but has a low precision for animals, this brings the whole metric down a lot. This also works vice versa: when a network has a perfect precision for trees, drivable surface, and cars but a low precision for cyclists it will still get a high mAP score.
Besides the score itself, we also see a problem with the annotations on which the network is evaluated. In the scene below, only three out of five frames have the tram lines annotated, and one of the three annotations is very coarse. In this case the importance of this class is low, but it still weighs the final metric down.





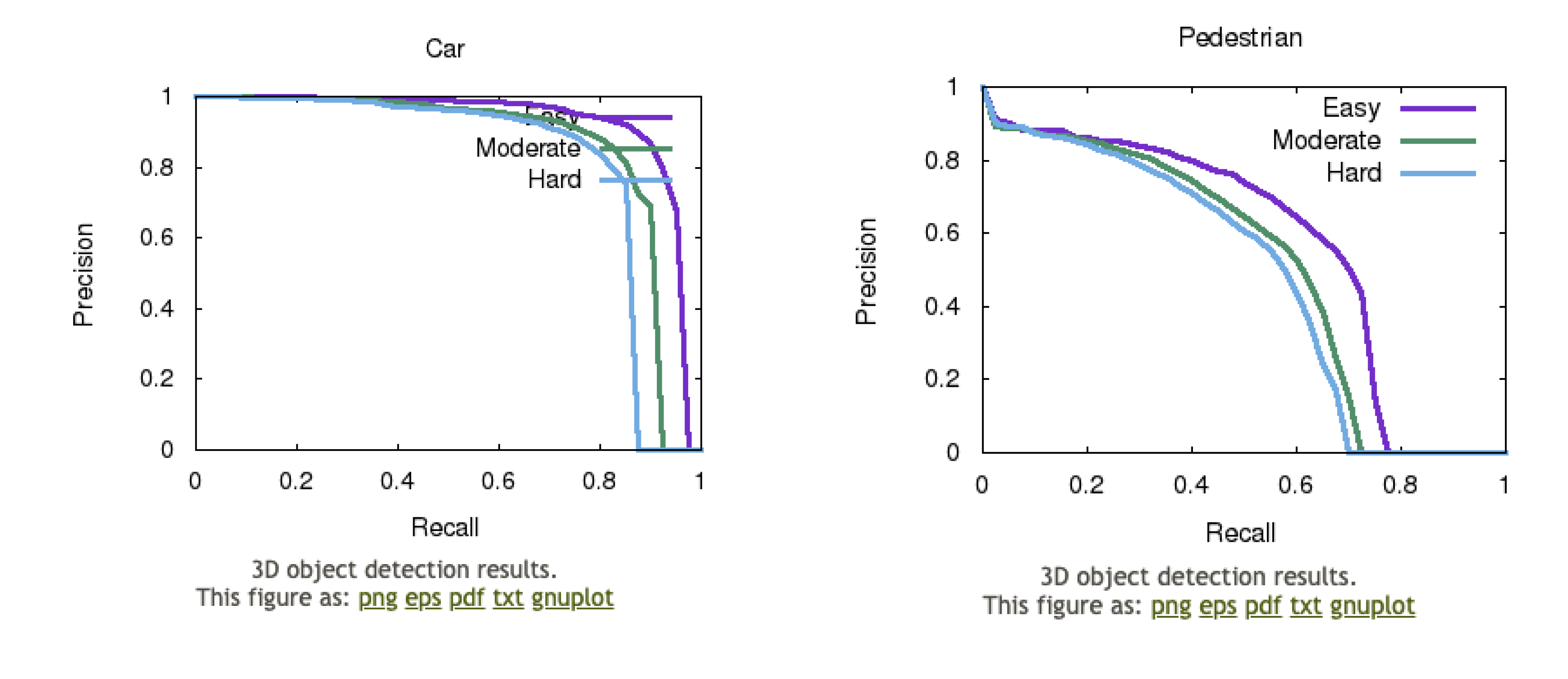
Let’s inspect another case, now looking at the metric rather than the input. The metrics below are the current benchmarking results for object detection on the KITTI dataset. Inspecting the precision-recall curves, we see that the model struggles even with the “easy” cases of pedestrians, with a maximum of recall still less than 80 %. For cars, the results look better. If all classes had that kind of average precision (ranging from 93.35 % for hard objects to 96.64 % for easy objects), would we deem it enough to go on the road? As it turns out, it’s very hard to decide on the exact expectations on precision and recall in object detection.
Our proposal: ‘Common Sense’
We believe that, before an autonomous vehicle hits the road, it has to pass a set of unit tests showing that the self-driving vehicle is at least capable of handling the most basic situations on the road. We propose this test by having coarse annotations of a scene with polygons which absolutely should be recognized by the AI. The aim is to capture a kind of common sense in the test, where we leverage the human understanding of what is important and not.
The reason for breaking the validation down to separate tests is to enable clear expectations of our validation metrics. If we take time to decide what is truly important in a smaller subset of the scenes, we know that we should expect that the model performs flawlessly there. If it doesn’t, it’s definitely not ready to go on the road.
As an example, in the scene above it is both very important that the vehicle knows there is a pedestrian on the left, and that cars are crossing the intersection. These indicate the presence of objects to recognize.
The road in front of the vehicle, i.e. the path the vehicle wants to take, is also important. This path, which is currently free of any objects, should also be recognised like this by our model. If our perception model would accidentally detect objects in this path the vehicle would likely make an emergency break, leading to discomfort as well as potential hazards. Because of this, we must test the car for both presence and absence of objects.
An example of a ‘Common Sense’ unit test
For this practical example, let's consider this frame from the CityScapes dataset. It is from the validation dataset, and was collected in Münster, Germany. In the frame, we see a car coming towards us, a car driving in front of us, and many parked vehicles on both sides of the road.

The coarse annotations available publicly for this dataset happens to nicely annotate the important vehicles on the road, as well as make a big block out of the parked cars. As such, this serves as a nice example of how one could have annotated only a portion of the (most important) objects. Therefore, we are going to use it as a unit test just like described earlier in this article. The annotations capture the important objects, excluding tricky or ambiguous edges, and so we know that we want a 100 % recall in order to let the model pass the test. We have no expectations on precision, as the model could very well (in fact, it even should) predict the edges of the cars outside of the coarse annotations. What is important here is that the model finds all the cars, i.e. that recall is 100 %.


Next up we take some model predictions. We took a model from the detectron framework which was trained on the Coco dataset. It does instance segmentation, among other things for cars, trucks, and buses. If we visualize the predicted instances for this frame we see the following:

Although this prediction looks relatively good, we do see some of the parked cars are missed. This makes it a great example to see if it passes or fails the common sense test. We plot the areas in the coarse annotations which overlap with our predictions in yellow, plot the predictions which are not overlapping with the coarse annotations in green, and plot the coarse annotations which are not predicted as red.

We see multiple red areas in this image, telling us that recall is not 100 % as specified for passing the test. This means that this model does not detect all the parked cars in the image, which could be dangerous during the actual driving and deployment. Therefore, this model should not be deployed and go on the road.
Different ways to construct the unit test

Let’s inspect a couple of different ways that a unit test like this could be constructed. In the left image above, we’ve annotated the presence of an object in yellow while to the right the pink annotation is marking the absence of objects. Both annotations are rough, not caring about exact shapes and edges. For the yellow presence-annotation, we expect the whole area to be found by the model. For the pink absence annotation, we expect that no objects are found in the area. These annotations can also be used together in the same test, and furthermore expanded to include edges and shapes. Let’s look at that next below.

On the left we have combined the annotations from above. Here we only make sure that the model finds the vehicle, and at least sees the center of it. For this model we don’t mind how sharp the edges are. In the same way, we only care that it does not detect objects in the center of the road.
In the middle, we assume the bottom of the vehicle (and some of its wheels) is actually detected. We also expect that the vehicle is not detected too close to us, by expanding the pink annotation upwards and closer to the car. However, the model is allowed to detect the vehicle ‘higher’ than it actually is, here what is tested is essentially the bottom of the car.
In the last example, we also limit the maximum height and right side such that the model has to have relatively sharp edges to pass the ‘common sense’ test. However, we still ignore the parked cars.
Extending this to 3D space
Not only can we have 2D polygons to indicate regions in an image, we believe that there is also value in extending this method to 3D. Especially for 3D bounding boxes in a lidar scene, there are many details which might not matter that much for which traditional methods are heavily punished. In LiDAR space it is often easy to recognize the exact dimensions of vehicles close to you, but very difficult to do so for objects far away.
For further objects, we see that even annotators don’t agree where the bounding boxes should be. We already wrote about this in our article on how perfectly we can reasonably expect annotations to be. We personally believe that a perception model should not be punished by your metrics for things even humans can’t agree on.
This is why we could extend the ‘common sense’ idea to 3D space using both ‘presence polygons’ and ‘absence polygons’. The ‘presence polygons’ indicate regions which a self-driving car should absolutely cover with a 3D bounding box. The ‘absence polygon’ indicates a region which should absolutely NOT intersect with any 3D bounding box.
As a simple example, a car seen from behind should definitely be annotated precisely at the back of the car. However, if it is impossible to know the length of the car, this should not matter when evaluating your algorithm. There is a limit to this, as if we can have a reasonable guess of the maximum length it should not be predicted to be longer than this length. This is why the car should be filled with both the ‘presence polygon’ at the visible part of the vehicle, as well as the ‘absence polygon’ at the place where the vehicle should NOT be seen anymore.
‘Common Sense’ in practice
We believe that implementing unit tests like this one can help both business and ML engineers in defining expectations for the model performance in their perception stack. In practice, we imagine that teams training and developing perception models construct these tests themselves. Such a process would allow for important discussions on trade-offs, uncertainty and the importance of different objects and agents in traffic situations. The way we see it, annotations like these aren’t done on a large dataset but rather on important scenes in a subset of the normal validation data. It does not replace, but complement, other means for evaluating object detection models.
Towards reliable cars on the road
Validating perception systems for autonomous vehicles is a hard task. One of the reasons the industry is struggling is because there aren’t feasible ways to define an exact expectation on most metrics used for object recognition with machine learning.
That is why we have proposed the usage of unit tests for predictions. Our presented approach brings human common sense into the testing and subsequent development of autonomous vehicles by allowing for specification of what is important in a scene. This enables practitioners to define the level a metric should reach when constraining the validation to this subset of the objects or scenes, thus allowing the otherwise impossible passing or failing of the system. For example, when only having marked the most important objects in a scene, we can actually expect that a good model should have a recall of 100% of those.
As such, these tests nicely complement currently used tests and metrics, and will help guide model improvements to eventually put reliable autonomous cars on the roads. ✨

