Since joining the ADAS/AD space in 2019, I've seen and read countless presentations about the potential of "data lakes," "scenario libraries," or similar. These are given by companies that have collected several petabytes of data, produced digital twins and/or annotations of parts they deemed interesting, and are now sitting on a mountain of data ready for use in simulation, ML training, virtual V&V, etc., available off-the-shelf. Is this data the treasure trove it's made out to be? Many feel very strongly that it should be - but as an AI expert once said to me: "Everyone likes to talk about how valuable their data lake is - but I have yet to see a single company list it as an asset on their balance sheet."

ML Shangri-La or cost sink? The value of data lakes heavily depends on their utilization.
First, credit where it is due: For ML-based product development, proprietary data definitely is a huge asset. While academic and research-oriented ML use cases tend to focus largely on algorithmic improvements, NN tweaks and hyperparameter massaging while relying on fixed datasets like KITTI, NuScenes, and similar, building a product-grade ML system is a different ballgame: Like Andrew Ng says when he talks about data-centric AI, in a market where everyone has access to pretty much the same algorithms that Google and NASA are using, product success depends largely on the effectiveness of your data effort. I’ve often referred to this as ‘programming with data’ rather than (only) with code. However, just as with code, a lot of data doesn’t equal a lot of progress.
Monolithic masses of data are an asset with a rather short half-life; one whose value begins to depreciate the moment you’ve stored it in your cloud or data center: Your camera supplier will discontinue the model that was used for certain recordings. The resolution of a reference LiDAR will be considered poor when the next generation comes out. New automation processes require higher-resolution IMU data or better timestamping. You realize you’d like to select data based on a marker that was not logged. Your scope eventually extends to objects or regions of interest that were previously considered irrelevant for annotation - and entirely new objects emerge that you never encountered a few years ago: people in masks during Covid, e-scooters, delivery bots, robotaxis … All datasets of real-world recordings inevitably suffer from such data drift as long as this weird and messy world keeps spinning and changing.

The value of static datasets inevitably suffer from data drift and knowledge drift.
And there is another problem: alignment - ensuring that machines behave the way us humans intend them to. You can’t really know which types of data create a positive effect on model performance until you start training, and the extent to which certain data types move the needle will change over time: If your perception performance is rather low, then yes - you can likely improve it by throwing tons of bounding boxes at the problem. If you are successful, however, you eventually end up at a point of diminishing returns and can’t brute-force your way forward anymore: 500k more labeled cars in front of the ego vehicle will not improve your recall for lost cargo, for example - and you can’t plot along which axes your long tail extends until you are well into your development effort.
Just as data drift is inevitable, you will also experience a ‘knowledge drift’ - initial assumptions about future data needs will give way to new insights about which types of data really have what effect at any given time. If, at that time, you are limited to data recorded and processed before your problem even was known, having suitable training data comes down to luck. And luck is a poor substitute for strategy.
The limitation of linear data pipelines
Legacy auto sometimes attempts to counter the resulting uncertainty by over-specification: I’ve seen sourcing RfQs outlining companies’ perceived data needs 4 years into the future, detailed over thousands of Excel lines - hundreds of which would suddenly be dropped just days before the proposal being due, but after that change, they will of course be perfect and need no adjustment for years…
Current-day ‘data pipeline’ efforts in a lot of companies are, in fact, waterfall models, looking something like this:

Linear data sourcing efforts make it a challenge to flexibly adapt actual ML development progress.
This is an attempt to build software the way one builds cars - and the execution of such linear sourcing efforts will result in low budget effectiveness: You are almost guaranteed to end up overspending on data/quality for which you overestimate the required needs while simultaneously suffering coverage gaps for data you did not expect to be as relevant as it ends up being - or a lack of objects/events you could not have predicted would come into existence after your requirements freeze. In short, thinking about your data effort as a “do once” effort means setting yourself up for expensive disappointment.
To refine is better than to repeat
So what should companies do with the massive data amounts they are already sitting on? Are they doomed to decline into worthlessness? And what about new data logging campaigns; are they predestined to fail because there will always be changes in the future? That’s too bleak of a look at things: While no one can offer a silver bullet to mitigate all data drift/knowledge drift challenges, we believe there are ways to increase the usefulness of legacy data without having to go through new data logging or re-labeling from scratch every time.
Rather than estimating needs upfront, we believe in accurately quantifying them along the way; and enabling a cascade of smaller, more budget-effective decisions based on such quantification. This can be achieved - quite easily, compared to other challenges in this field - by integrating your data effort with your ongoing ML model development. The overall process we propose for supervised learning is outlined in this article.

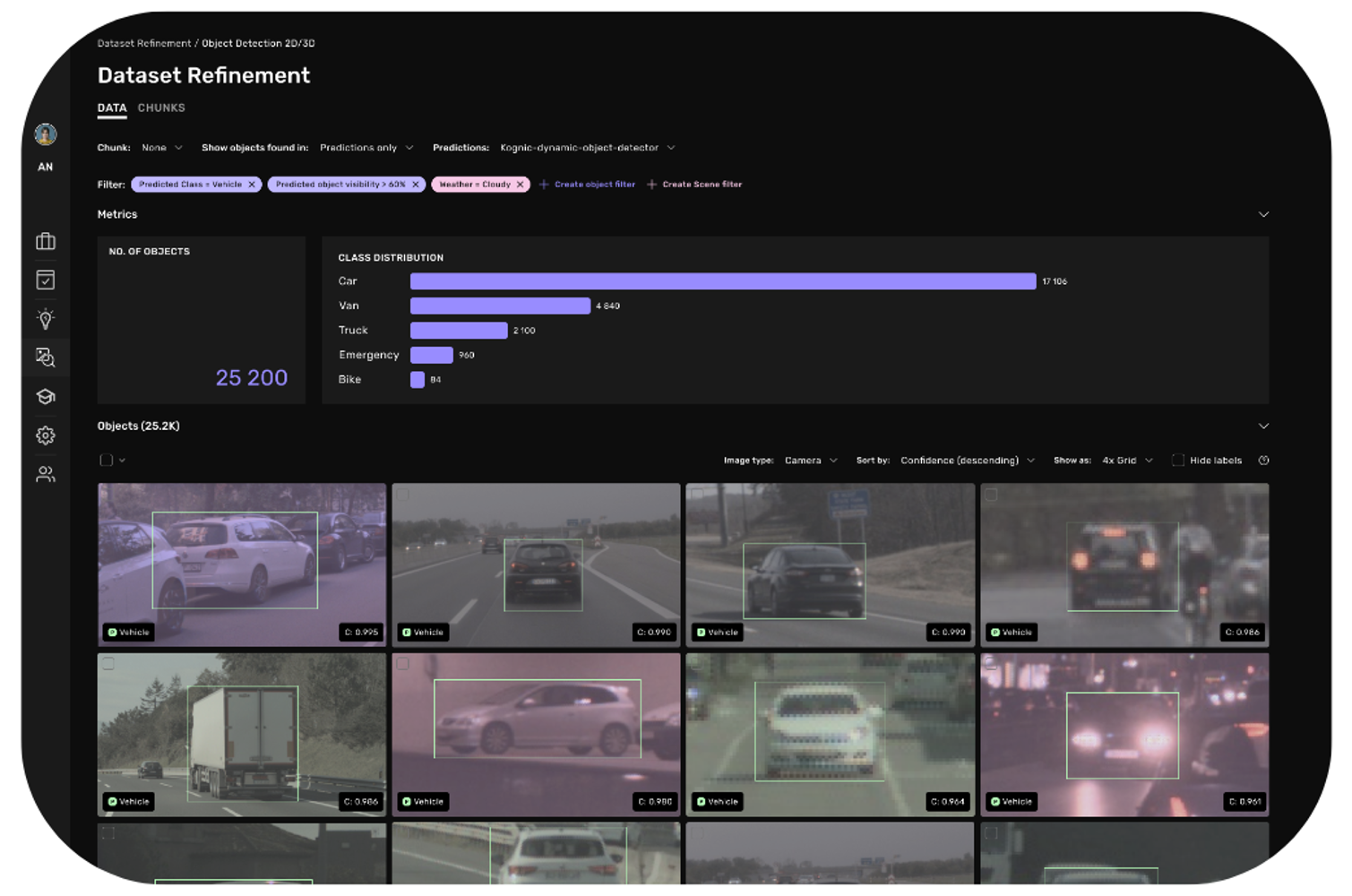
Using model predictions to analyze training datasets and vice versa: Integration of data/development efforts allows for faster iteration
Generally speaking, we believe that you should treat your dataset as an asset that’s “under development” just as much as your algorithms - the upkeep of which requires adequate developer tools, just as working with code does. Leveraging such tools, you can easily use one dataset to ‘interrogate’ the other; using your model-under-development to bring all the maintenance-relevant portions in your datasets to the surface - so they can be sent for an update (not re-annotation from scratch) and made available in just the configuration you need for your current training effort.
The (business) case for integrating data and model development
Are we writing this article to sell you software? Absolutely. We think the buy is pretty much a no-brainer: If you want to keep the return on investment for your data lake at an acceptable level, you need to invest in maintenance. Just as any codebase will degrade and drown you in ‘technical debt’ if not kept up-to-date, the same happens to data.
So we believe that regularly dragging the bottom of your data lake makes a ton of sense - lest you eventually end up with a swamp. And the results speak for themselves: The first lead customer to try Kognic’s exploration tools has found the effort to be the one initiative that had the single-biggest impact on their ADAS perception development during the whole year.
We like the sound of that, but we want to build more proof - and that is where you come in: Kognic is currently looking for one or two additional lead customers to test drive Explore in a limited-time pilot engagement - either using old ground truth data you already have or in an entirely new effort, including labeling in the face of unclear data needs.
If you believe in iterative software development and agree that iterative thinking must extend to the data effort, then we want to talk to you: Hit the “Book a Demo” button in the top right, or reach out to us via my email address below. We look forward to exchanging thoughts!


